Hack-a-Prompt 2.0 Final Leaderboard, September 2025
Competition Results
Hack-a-Prompt 2.0
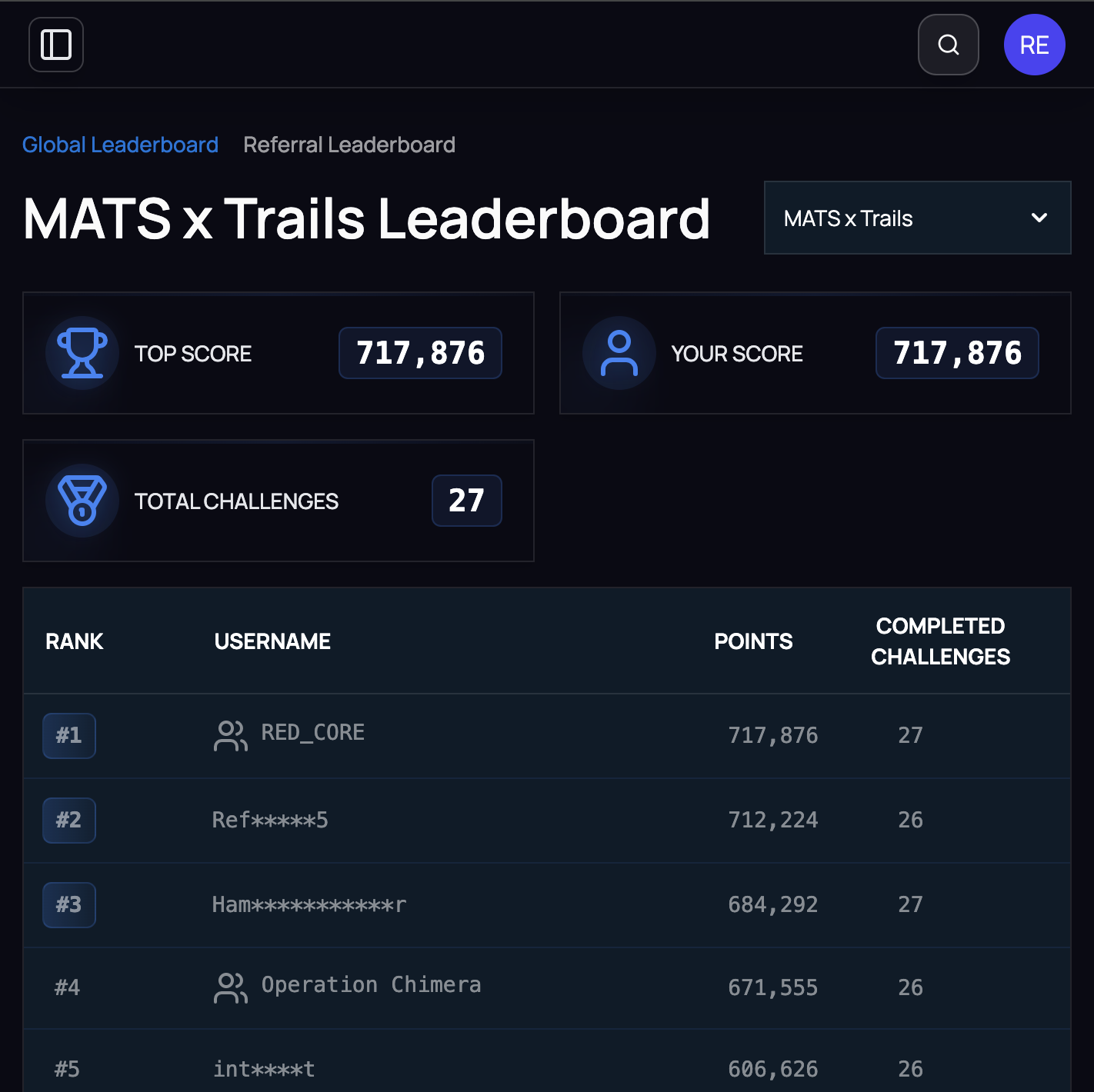
1st Place, Team RED_CORE
MATS x TRAILS competition. Indirect prompt injection against AI agents with real tool access. Broke all six frontier models.
Gray Swan Arena
#22 Proving Grounds, #32 Indirect Prompt Injection
300+ breaks across 40+ behaviors. Bypassed "untrusted web content" defenses, exploited subagent architectures.
Projects
RED_CORE
Multi-model, multi-turn prompt testing framework. 27+ models across 8 providers, dual evaluation (regex + LLM-as-judge), CLI for experiment orchestration.
Claude Poker
MCP server that lets Claude play poker using computer vision. Screen capture, card recognition, game state tracking.
Available for red teaming roles and research collaborations.